
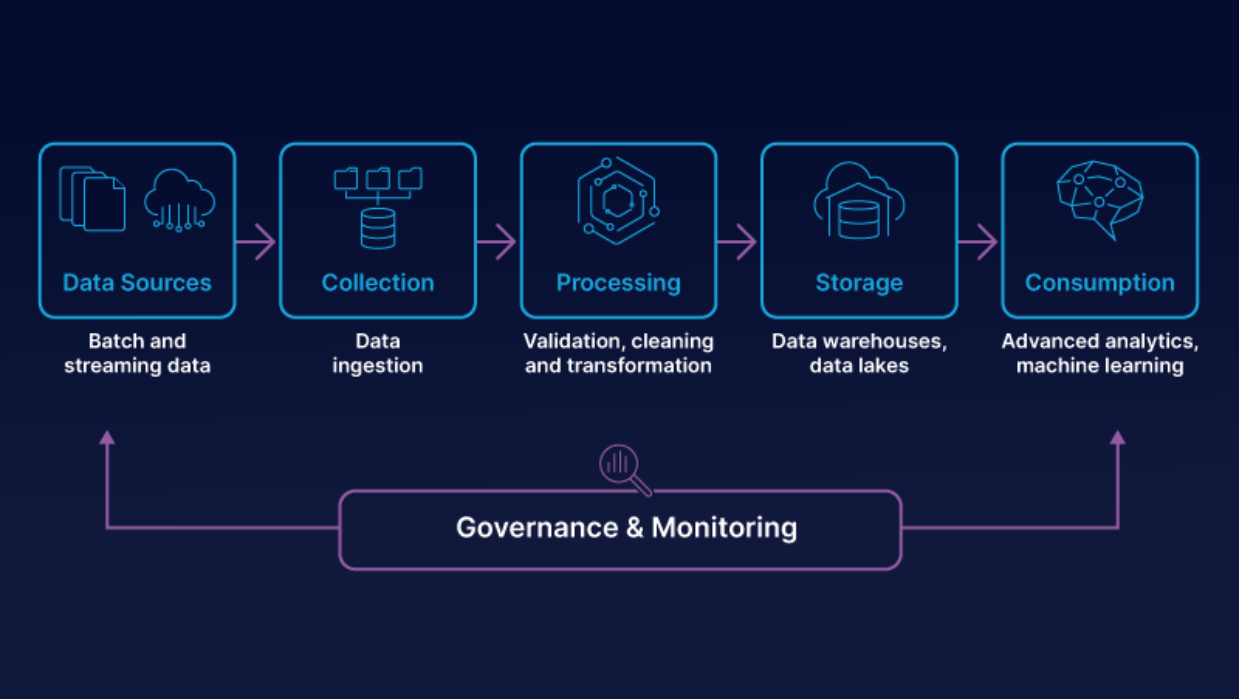
Efficient data management practices are crucial for handling neuroimaging data. Building a data pipeline from start to end is often required for neuroimaging data to ensure efficient, accurate, and reproducible analyses.
- Once data is acquired, the data must be structured in a standardized format for easy access and analysis. Version control is a part of this practice to track changes in data.
- The data is then preprocessed which involves quality control (checking data quality), normalization (aligning images to standardized anatomical space), smoothing (applying filters to reduce noise and improve signal-to-noise ratio), and so on.
- Following this is data analysis, visualization, interpretation, and reporting.
- An ongoing feature of this process is pipeline automation (using software and scripts to automate tasks) and assessing scalability to ensure the pipeline can handle increasing data volumes and complexity.
For example scripts from this pipeline, please check out my Github