
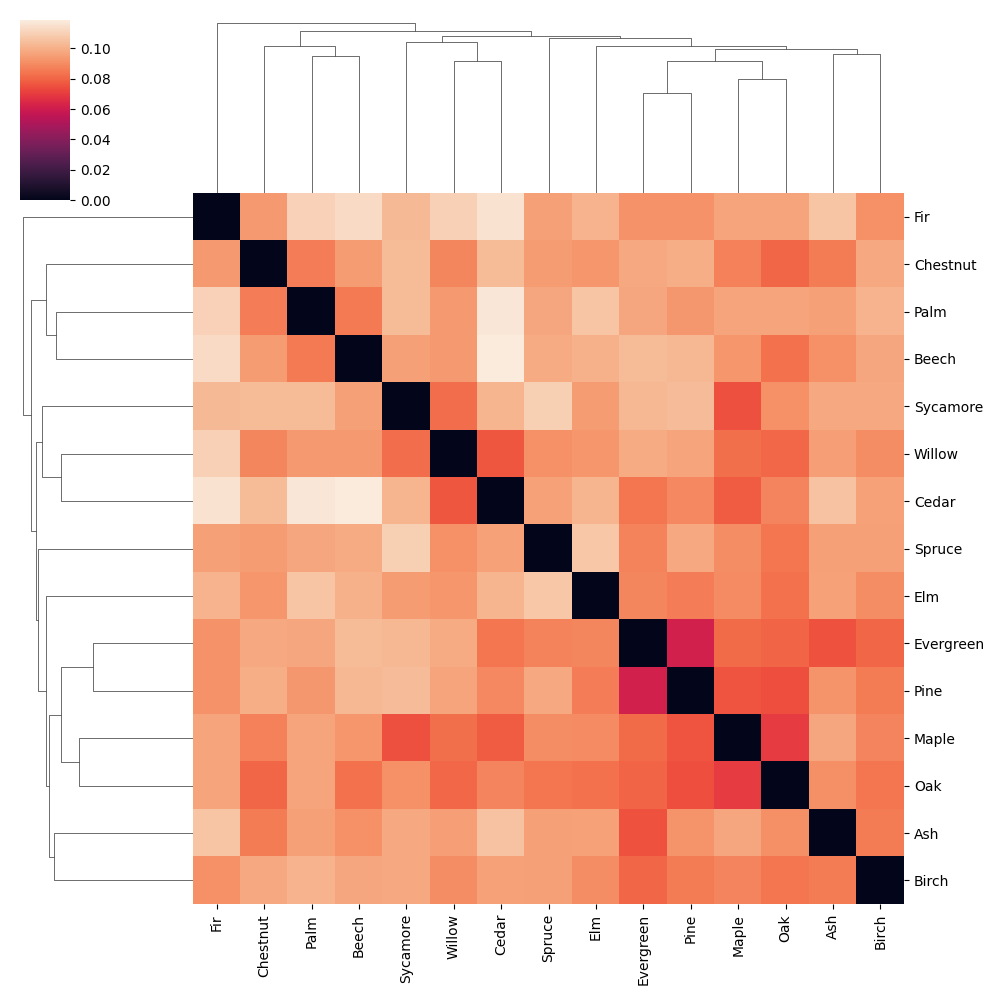
K-means clustering enables us to uncover underlying structures and associations, facilitating deeper insights and more efficient data processing.
In the context of semantic spaces, where concepts are represented as vectors in high-dimensional space, k-means clustering can effectively group related concepts together. By analyzing the proximity of vectors, k-means identifies clusters of words or concepts that share similar semantic meanings.
For example scripts, please check out my Github